
服务哨兵-sentinel
服务雪崩
什么是服务雪崩?
服务雪崩是一种因”服务提供者的不可用”导致”服务调用者不可用”,并将不可用逐渐放大的现象
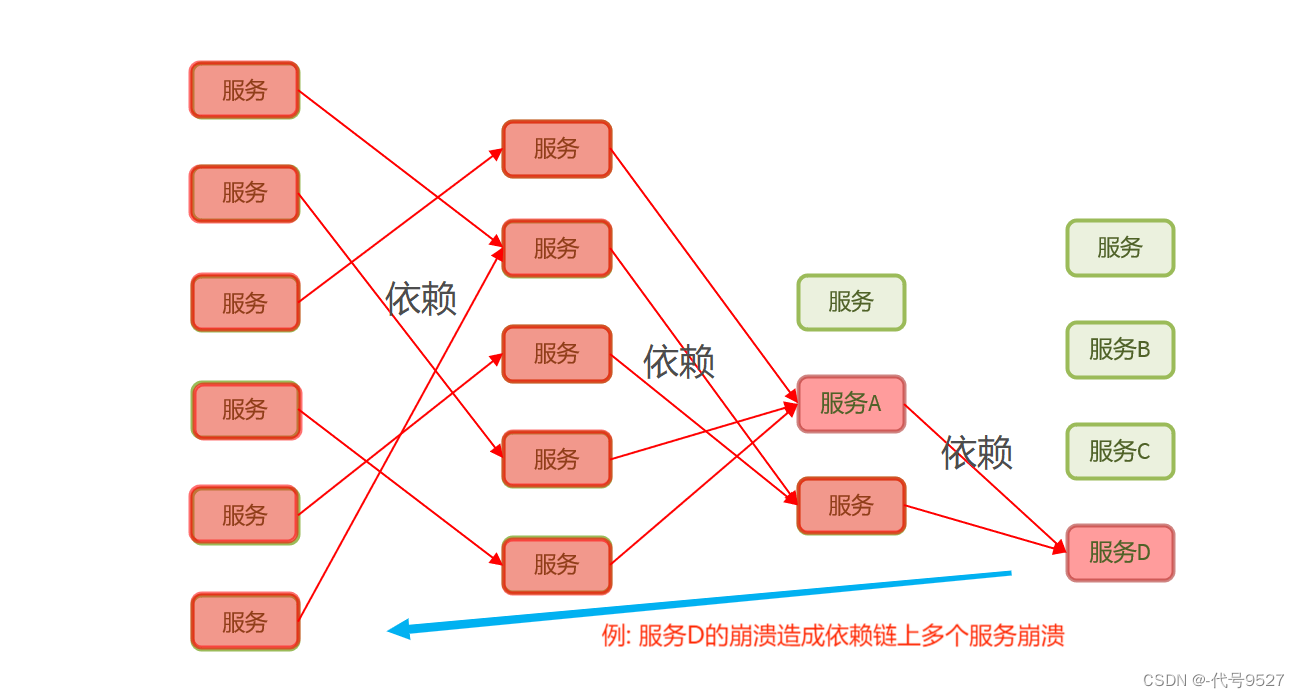
雪崩的原因及三个阶段
阶段一: 服务不可用
– 硬件故障
– 程序BUG
– 缓存击穿 -> 例如一个程序是通过id号查询其详细信息,我们利用redis缓存保存一些热点信息,当一个查询的id不在缓存内时,会转向数据库查询这些数据,每次访问这些数据都会直接去查询数据库里面的信息
– 用户的大量请求
阶段二: 调用端的重试加大流量(例: openfeign的底层使用了重试器,当用户发送请求时,发生了网络抖动,导致请求无法在规定的时间的时间内拿到数据,这时重试器会再次发送这个请求,再次对数据进行拉去)
– 用户重试
– 代码逻辑重试
阶段三: 服务调用者不可用 ->同步等待造成的资源耗尽
解决方案:
流控限流
缓存预加载
服务降级(保留重要的服务关闭不重要的服务;降低一致性)
服务熔断
舱壁模式 规定每个业务的最大线程数
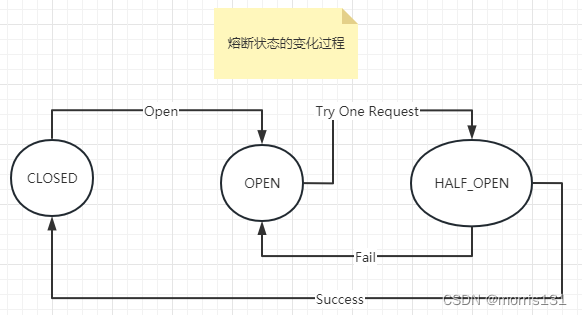
服务熔断-断路器模式

最开始处于closed状态,一旦检测到错误到达一定阈值,便转为open状态;
这时候会有个 reset timeout,到了这个时间了,会转移到half open状态;
尝试放行一部分请求到后端,一旦检测成功便回归到closed状态,即恢复服务;
Sentinel
概念
Sentinel 是一款开源的,且功能强大的流量控制和熔断降级框架,用于保护分布式系统的稳定性和可靠性。它主要用于应对高并发访问、突发流量和异常情况下的服务保护和流量控制。
Sentinel以流量为切入点,从流量控制熔断降级,系统负载保护等来保障服务的稳定性.
组件与功能
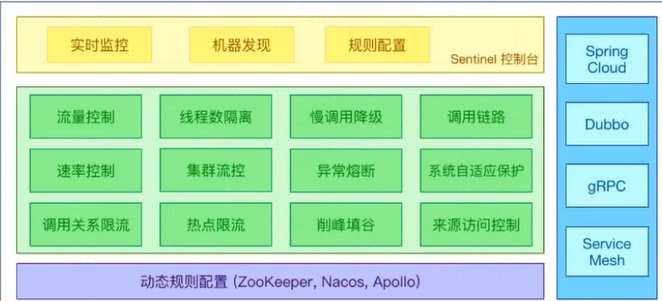
多种限流算法:包括令牌桶、漏桶等,可以根据业务场景选择合适的算法。
多种限流维度:包括QPS、并发线程数、异常比例等,可以根据不同的维度来进行限流。
多种应用场景:支持Dubbo、Spring Cloud、gRPC等多种RPC框架的服务发现和调用。
动态规则源:支持多种数据源,如Nacos、Zookeeper、Apollo等,可以动态推送和更新规则。
实时监控:提供实时的监控和统计功能,可以查看服务的运行状态和指标
Sentinel本地项目
引入依赖-核心库
1 | <dependency> |
定义资源
1 | public static void main(String[] args) { |
规则配置
1 | private static void initFlowRules(){ |

要进行的操作表示服务正常运行
blocked!表示每秒的请求数超过规定的20000次被拒绝
Sentinel控制台
Sentinel安装与配置
安装sentinel-dashboard-1.8.6.jar
下载地址: https://github.com/alibaba/Sentinel/releases/tag/1.8.6
启动
新建一个
.bat后缀的批处理文件,以java命令启动
1 | // `./` 与该文件同级下的sentinel-dashboard-1.8.6.jar文件 |
访问Sentinel控制台
默认用户名密码都为sentinel
引入依赖
客户端信息需要用HttpClient接入到Sentinel客户端
1 | <dependency> |
配置启动参数
指定控制台的地址和端口
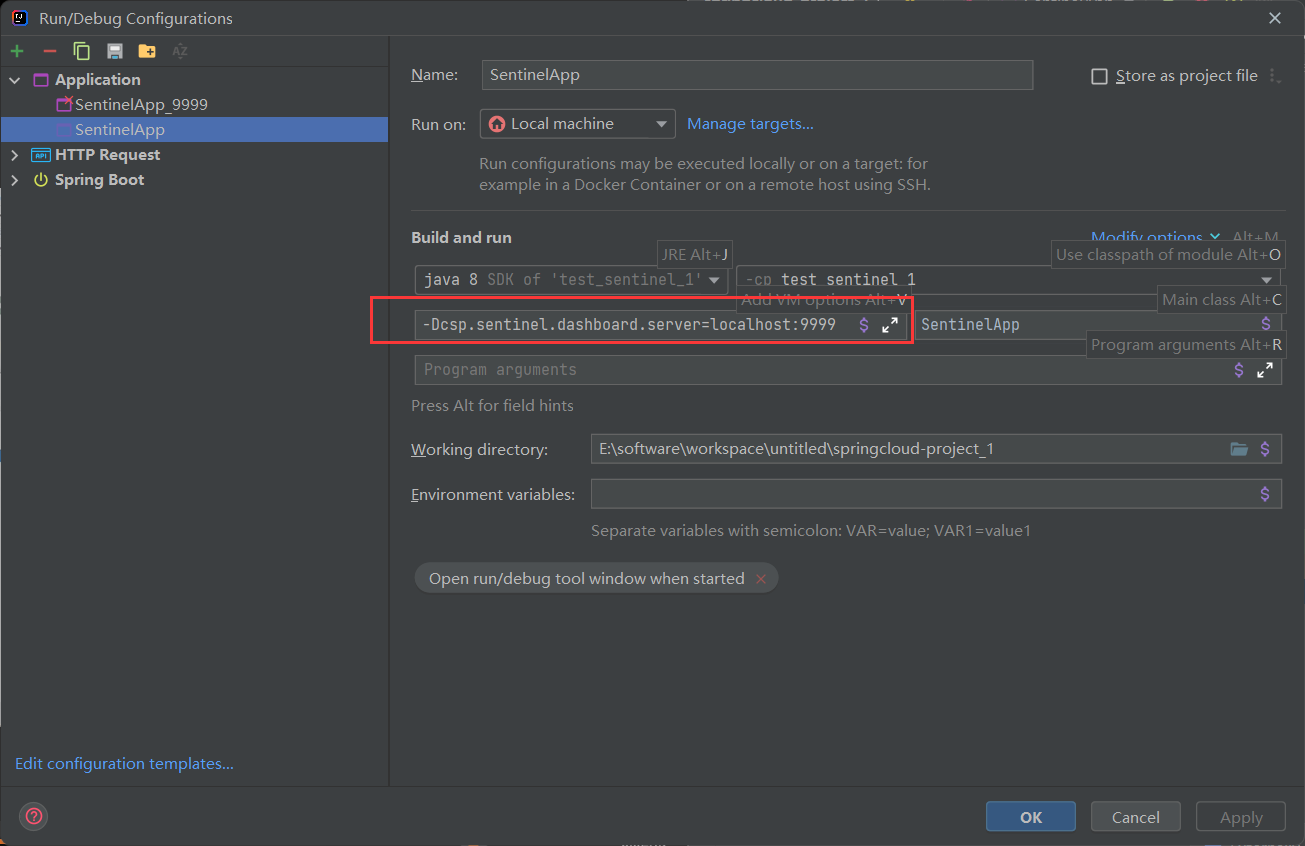
服务连接sentinel控制台
启动SentinelApp,在控制台查看详情(图表可视化)
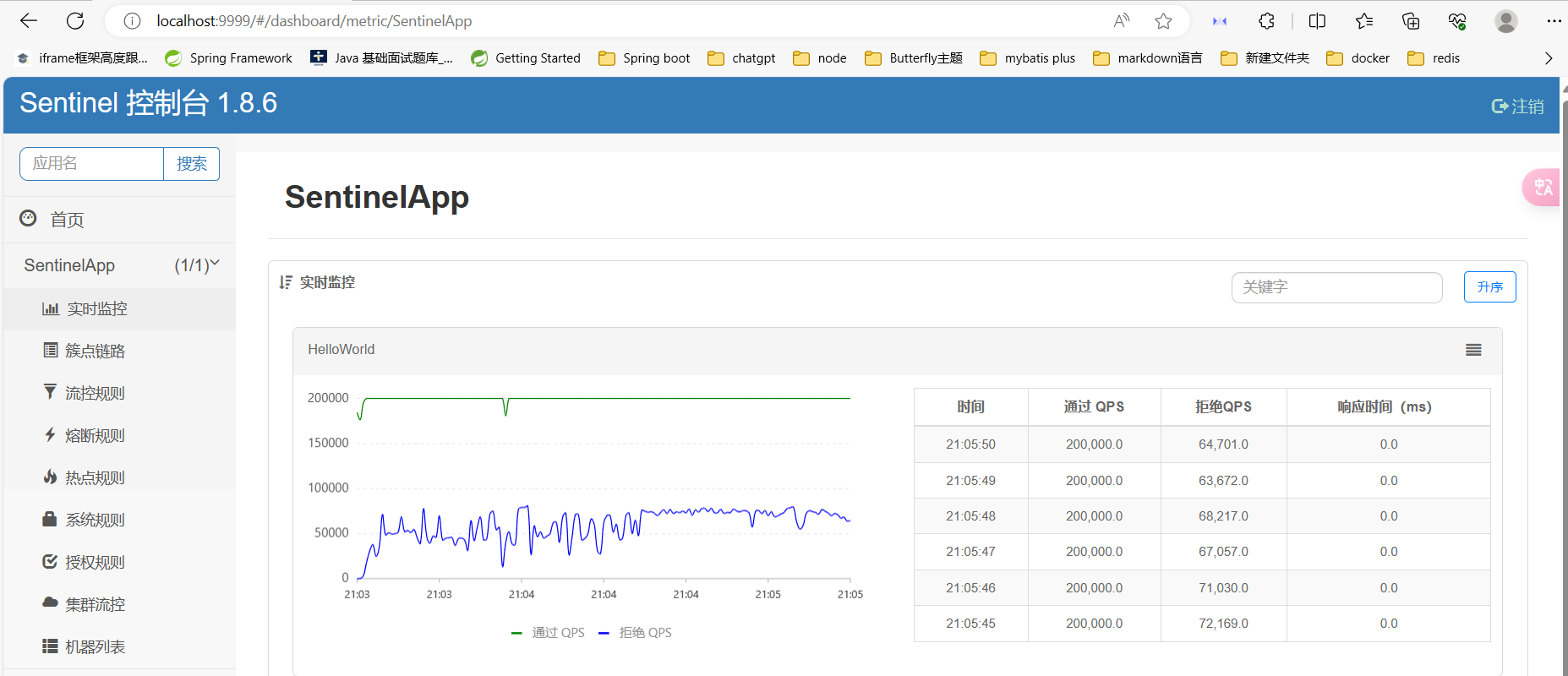
动态修改阈值
Sentinel控制台动态修改阈值,通过实时监控,可以看到阈值可以通过控制台在程序运行时动态实时修改
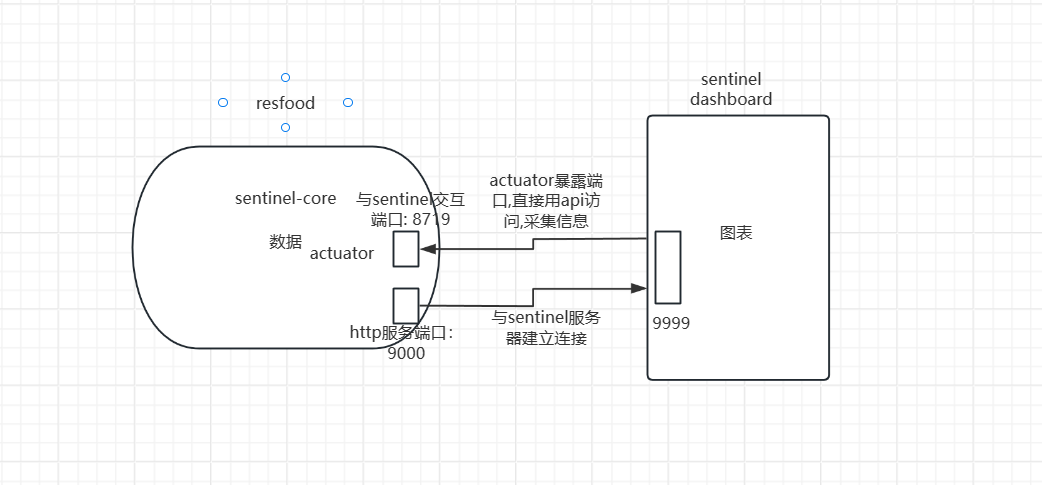
微服务整合Sentinel客户端
原理图
1.引入依赖
重要子依赖
simple-http:它是一个简版的http服务器,用于与dashboard通讯,Sentinel中的simple http是一种提供HTTP端点的通信模块,用于接收来自Dashboard的控制指令
aspectj的依赖: 用于完成对目标资源的统计(流量QPS)工作(aop)
1 | <!-- sentinel 客户端依赖 --> |
2.yml中配置sentinel服务
在nacos配置中心的resfoods的配置中修改,如果使用了负载均衡策略有该项目多个配置文件,可在不同的配置文件中配置不同的sentinel端口即可
1 | spring: |
3.测试
启动项目建立与sentinel夫区埃的连接,使用Jmeter测试是否可以对客户端进行监控
熔断降级
原理图
慢调用
慢调用RT(最大的响应时间)
请求的响应时间大于RT则统计为慢调用
当单位统计时长(统计窗口时长)内请求数目大于设置的最小请求数目,并且慢调用的比例要大于阈值,接下来熔断时长内的额请求会被自动熔断(同时满足两个条件)
示例:
1 |
|
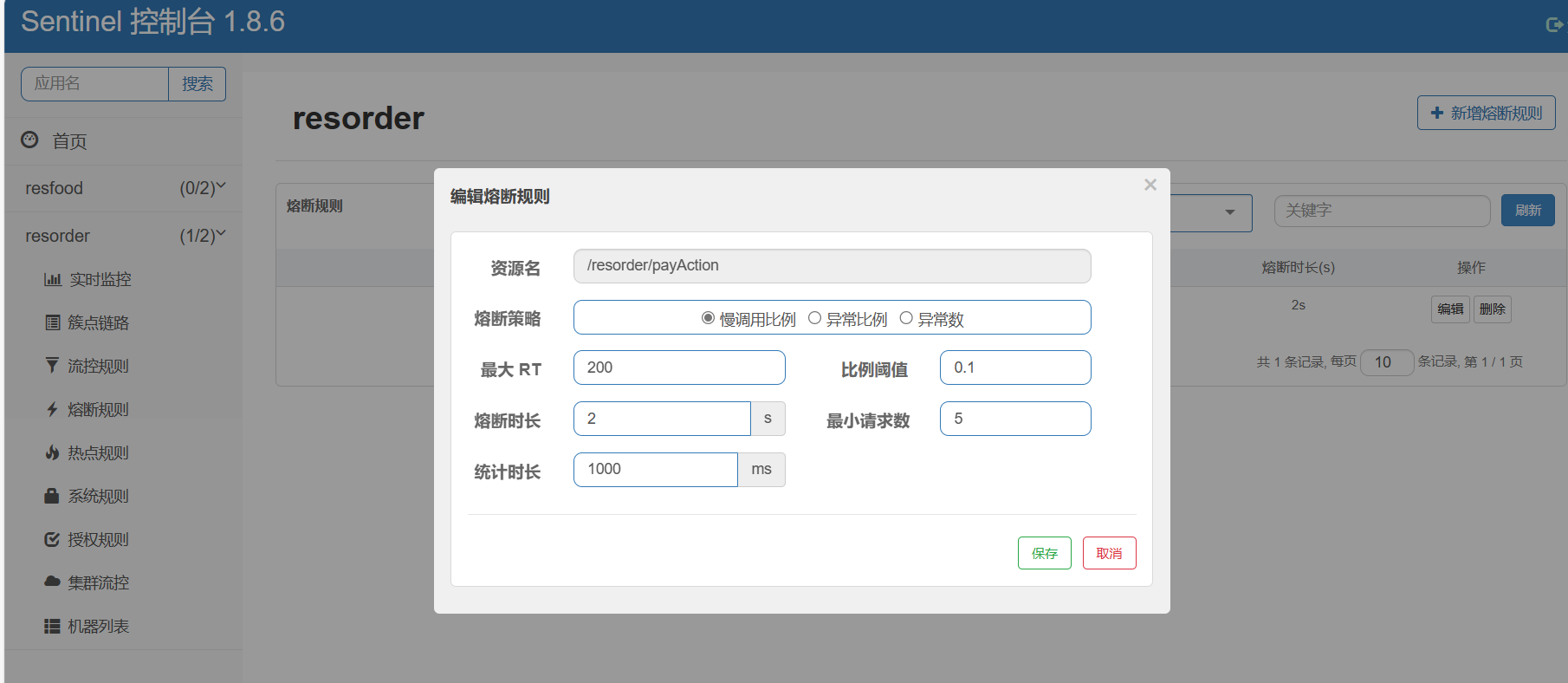
sentinel控制台配置熔断规则
在Apache Jmeter里配置请求
100个请求分5秒发送,每秒20个请求
发送请求,查看控制台实时监控图
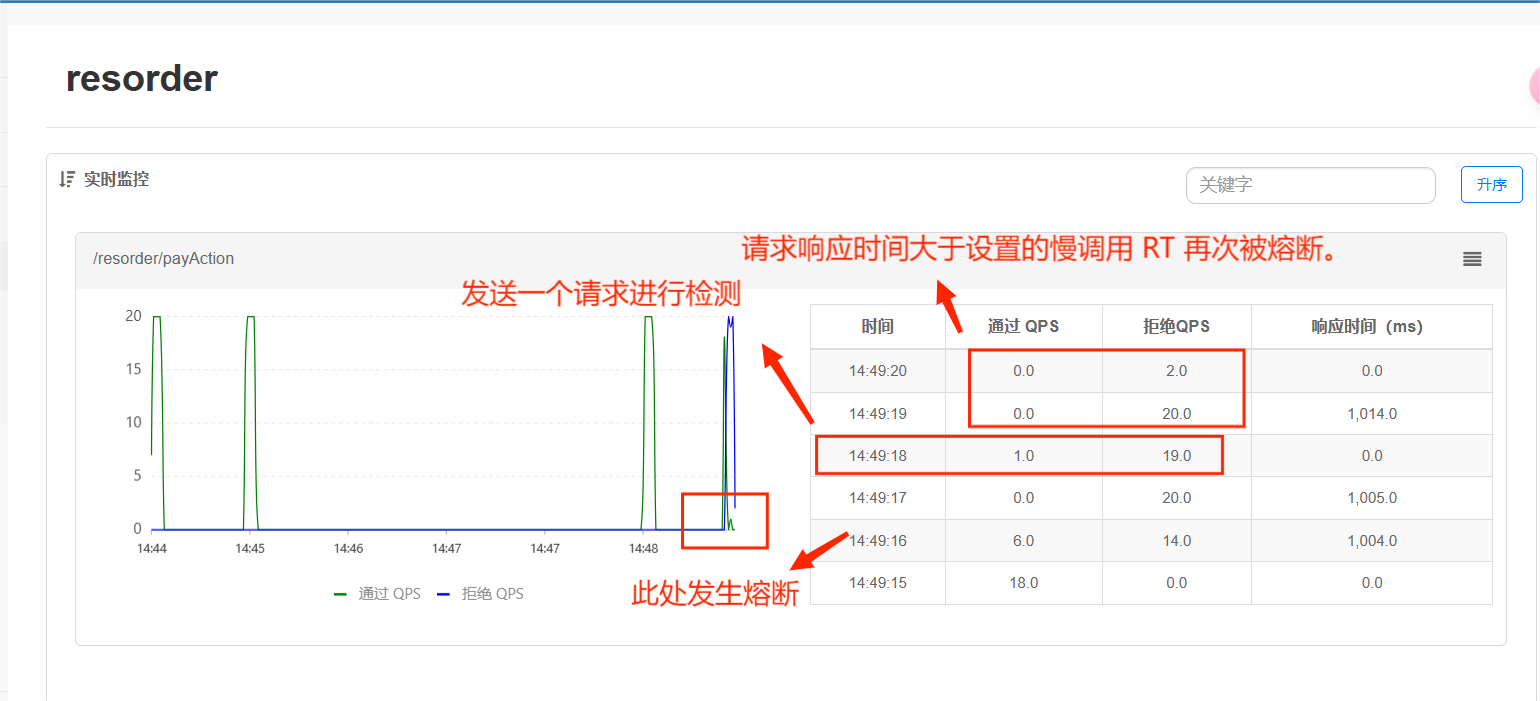
如图14:49:16 - 14:49:18时刻,14:49:16时刻单位统计时长内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,发生熔断,在熔断这两秒的时长内,也就是14:49:18时刻发送了一个请求测试是否有响应,经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态)
异常比例与异常数
示例:
1 |
|
在Apche Jmeter中查看详情
通过测试可以得知当前异常比大约为40%
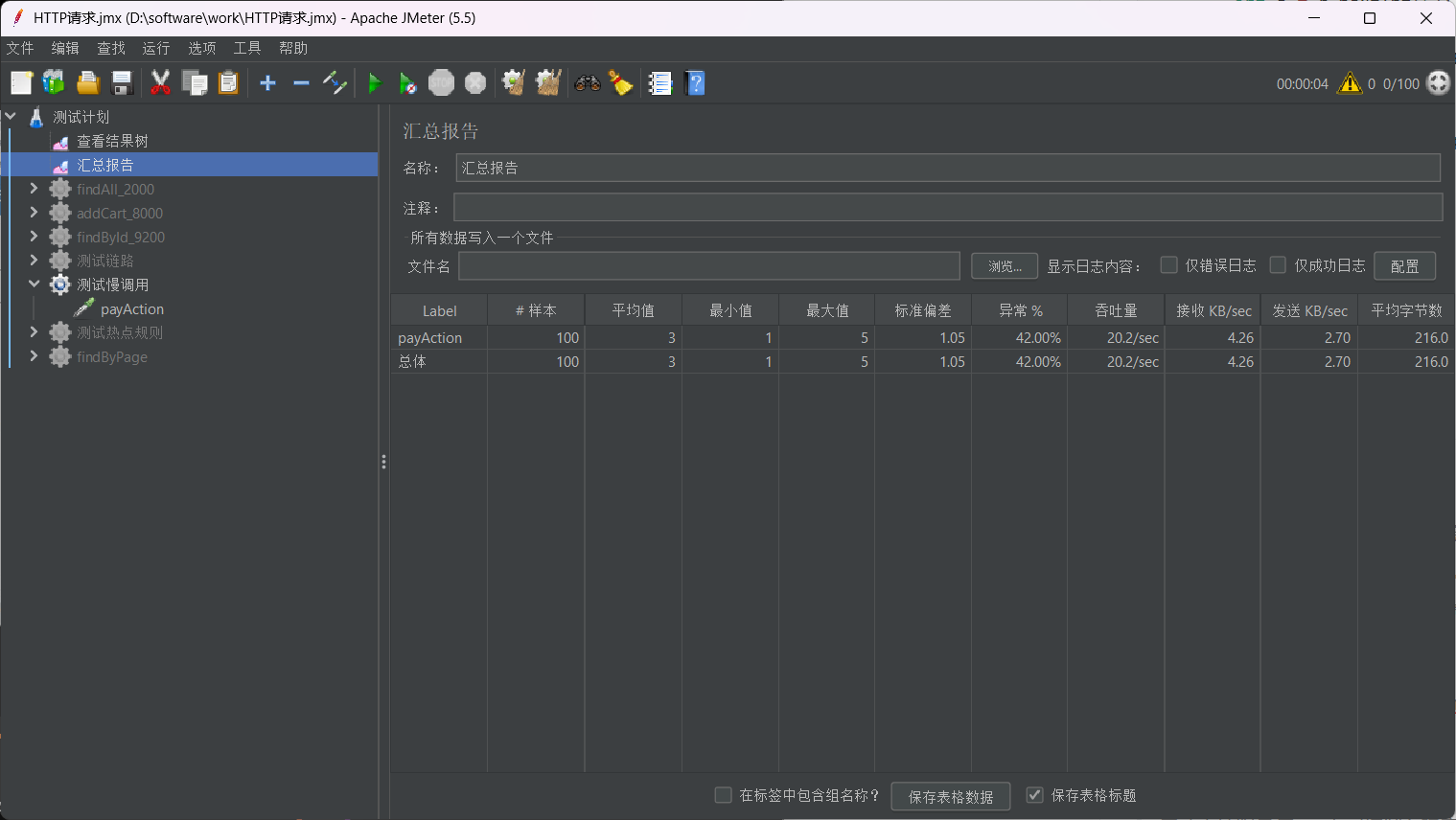
配置熔断规则
这里异常数配置为6是因为,发送的请求的异常比例为40%,又因为每秒的请求数有20,当异常数为8的时候,异常比例为40%,设置为6说明我们模拟的环境是发生熔断的条件是低于40%异常比(阈值低于0.4),而程序中的异常比规定为40%,异常的比例大于阈值发生熔断
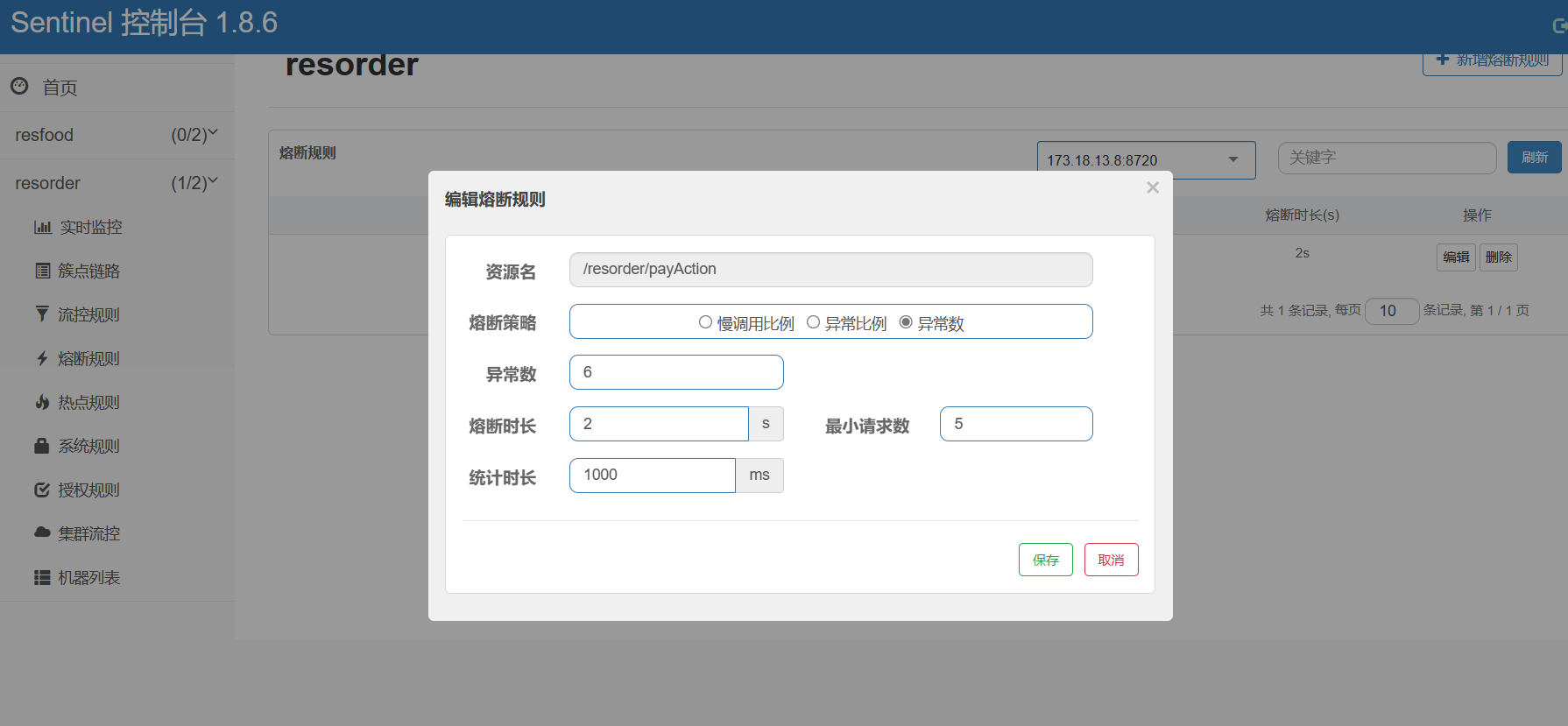
Apche Jmeter重新发送请求,查看控制台监控图
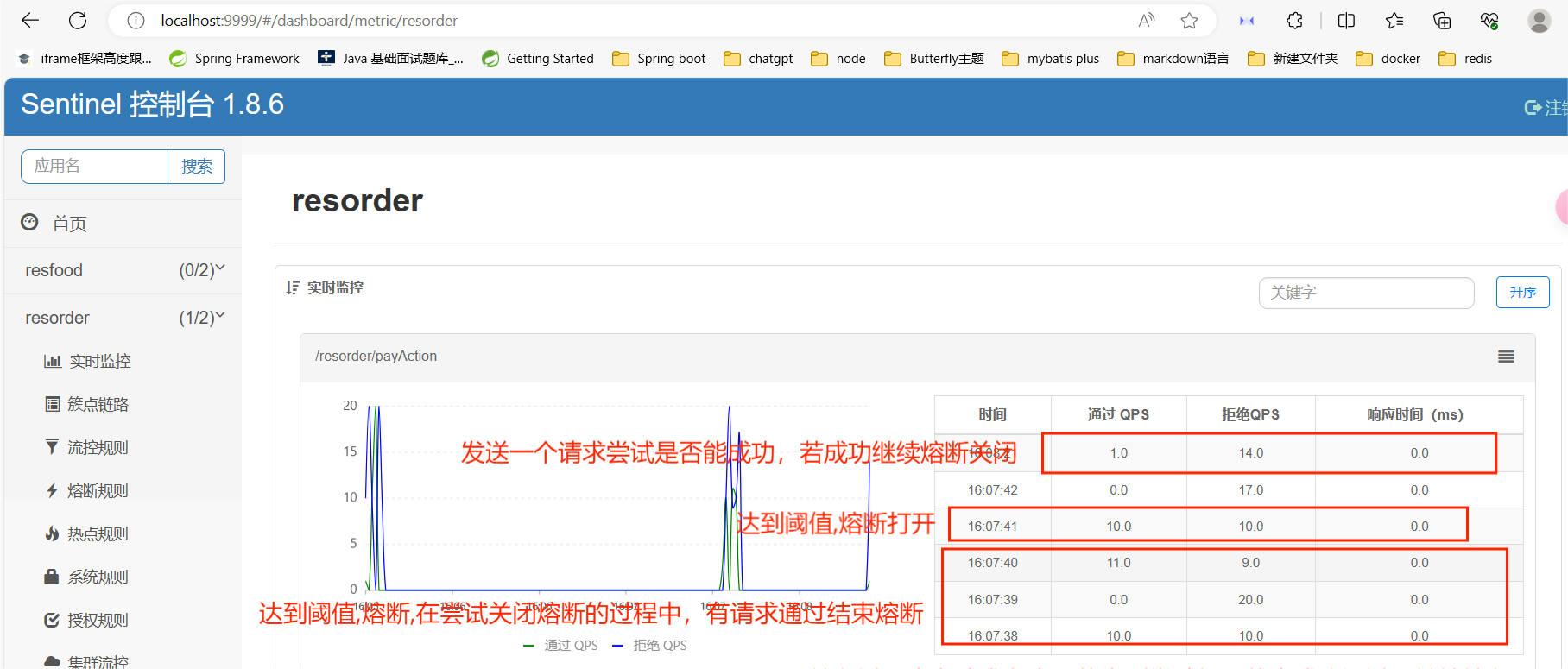
流控
阈值类型:
QPS: 单位实践类,请求接口数限制并发线程数: 单位时间类, 请求并发数限制
单机阈值: 每秒限制的次数
流控模式: 直接 快速 失败
流控效果: 快速失败 Warm Up 排队等待
快速失败: 单位时间内请求数超过阈值直接拒绝
Warm Up预热时间: 冷启动,在预热时间内请求数慢慢增多直至达到达到阈值,但不超过阈值
排队等待: 在超时时间内,所有请求根据阈值限制,均匀排成多个队列进行排队等待
关联流量控制
防止两个或多个资源之间有资源争抢而影响资源吞吐量
比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢
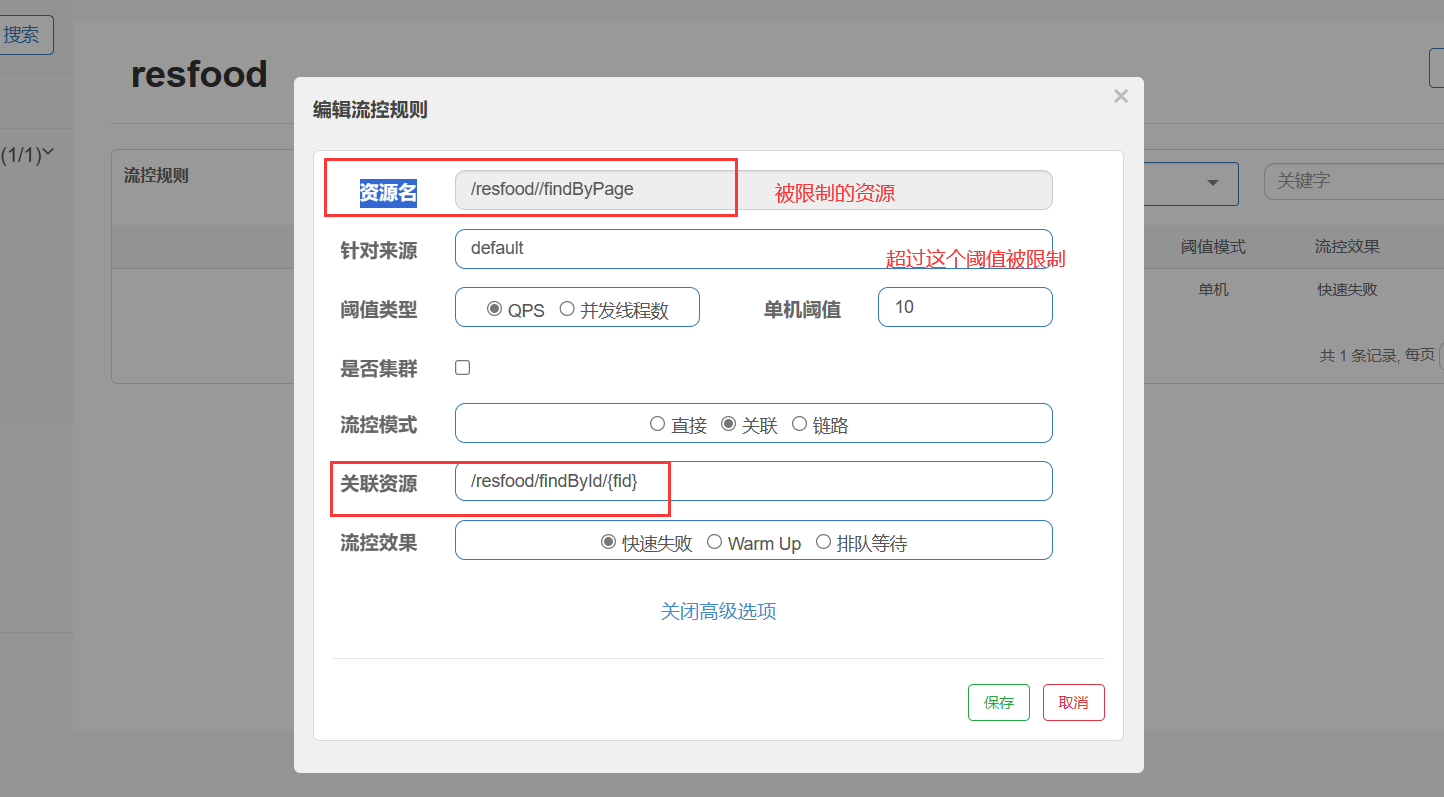
热点限流
控制热门资源的访问流量,以避免资源过载
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控
1.定义资源
在需要限流服务的方法上加入@SentinelSource(“流控资源名”)
2.启动服务
启动本地服务与sentinel控制台建立连接
3.测试
在Apache Jmeter上配置请求,每秒100个请求,循环一次,每个请求访问第一页数据
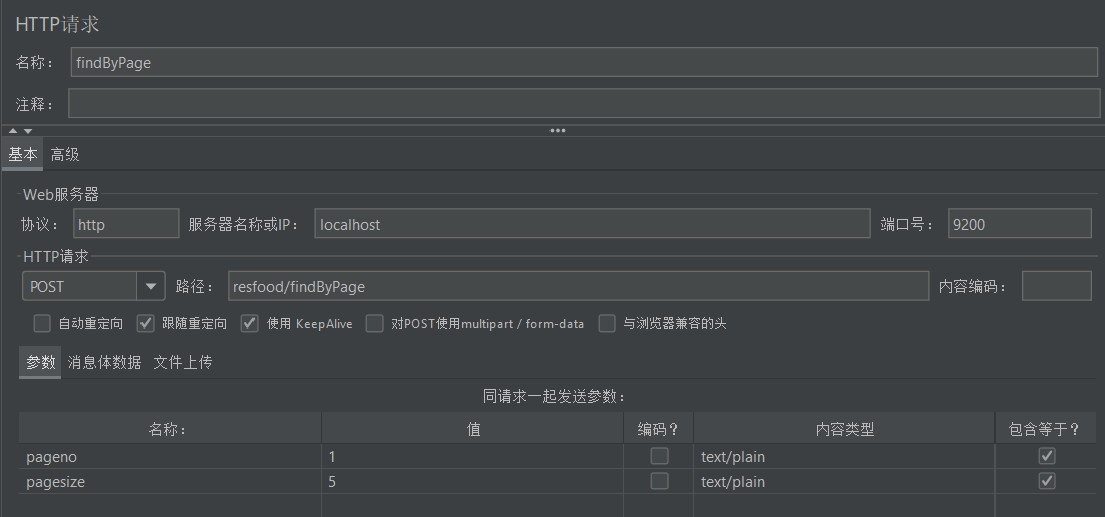
在sentinel控制台编辑热点规则
这里对请求进行了限流,限定了只接受两个请求
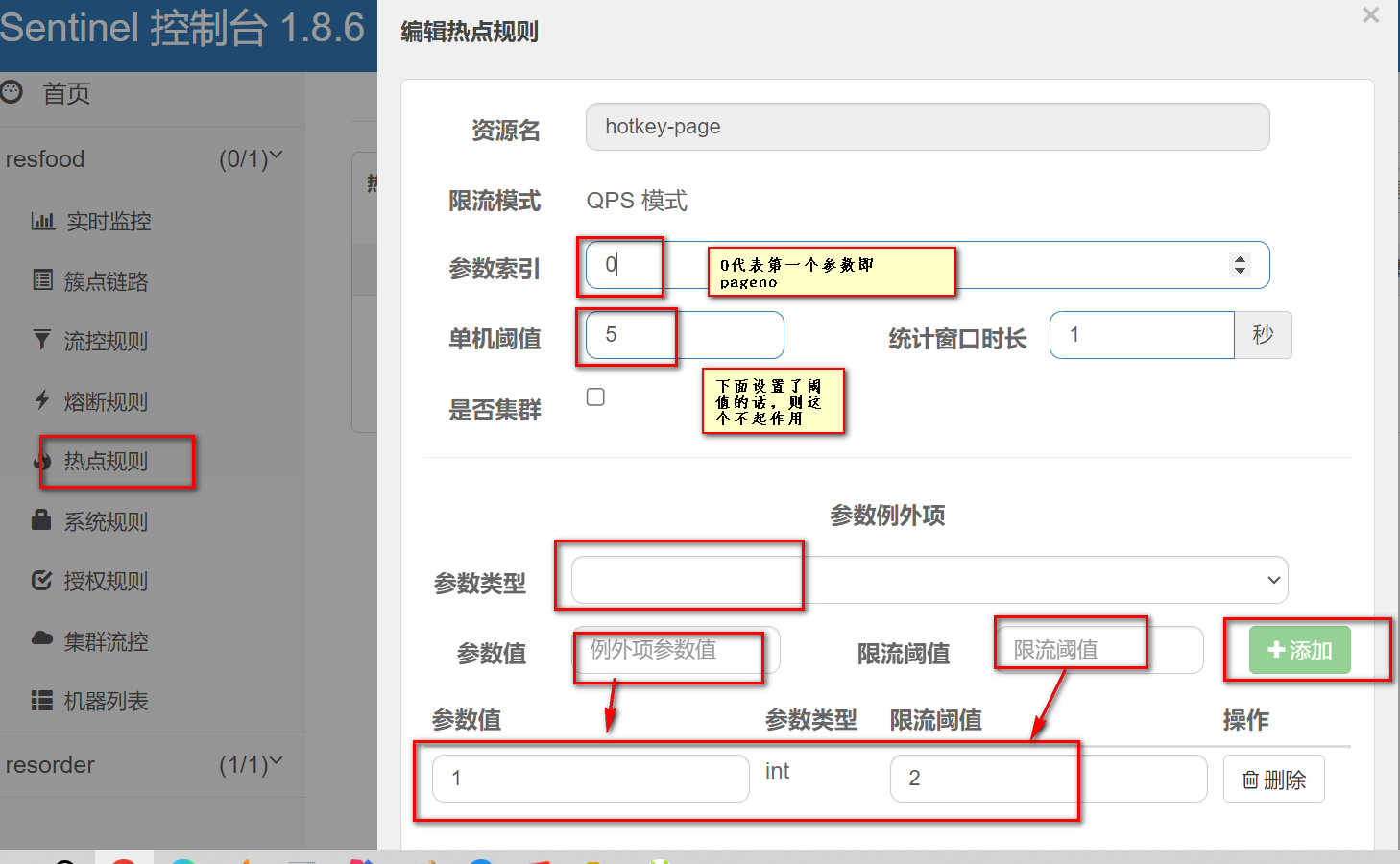
在实时监控图中可看到只有两个请求通过,其余的请求被拒绝
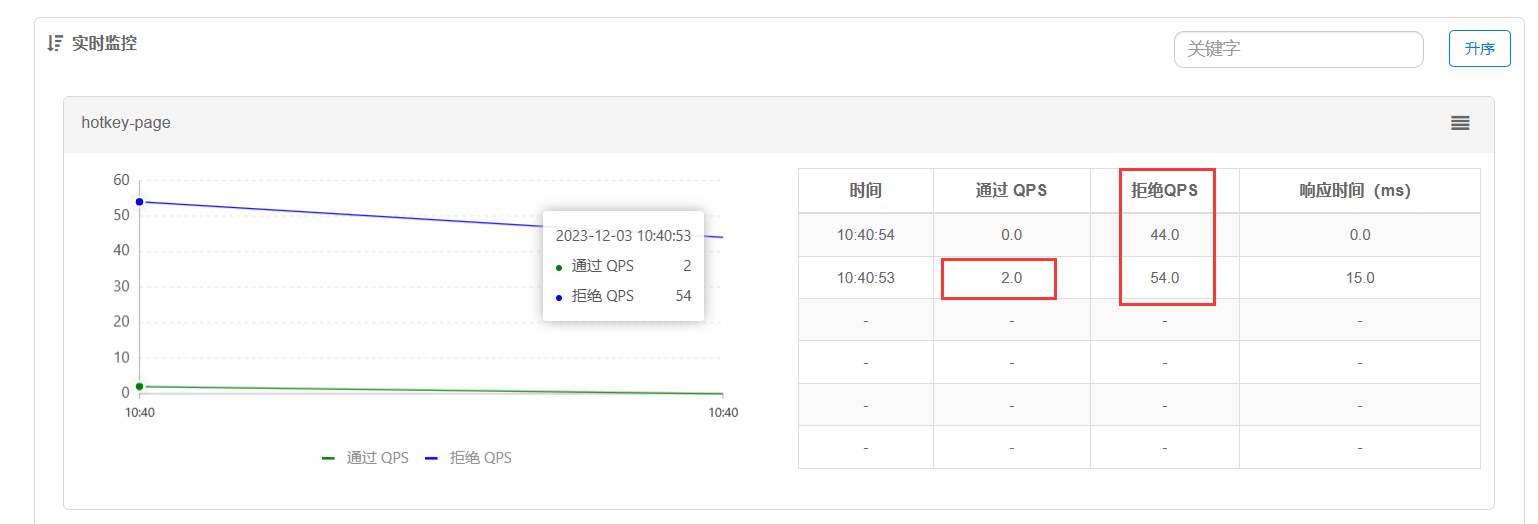
链路限流
只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就可以限流)[api级别的针对来源]
示例
1.关闭默认整合链路功能
sentinel底层统计链路信息的时候,将多个入口的请求做了合并
machine-root / \ / \ Entrance1 Entrance2 / \ / \ DefaultNode(nodeA) DefaultNode(nodeA)请求不管从哪个入口进入都会进行计数,所以需要关闭默认整合链路功能,每条链路单独计数
1 | spring: |
2.示例
模拟订单的两个统计功能,无论哪个统计都需要访问商品信息
goodsInfo
/ \
/ \
serviceA serviceB
业务类
1 |
|
controller类
1 |
|
Apche Jmeter
一个线程组添加两个Http请求 serviceA serviceB
参数:
- 线程数 100
- Ramp-Up 1
- 循环次数 1
流控规则配置
这段配置的意思是只要goodInfo的调用次数超过2就限制service的流量
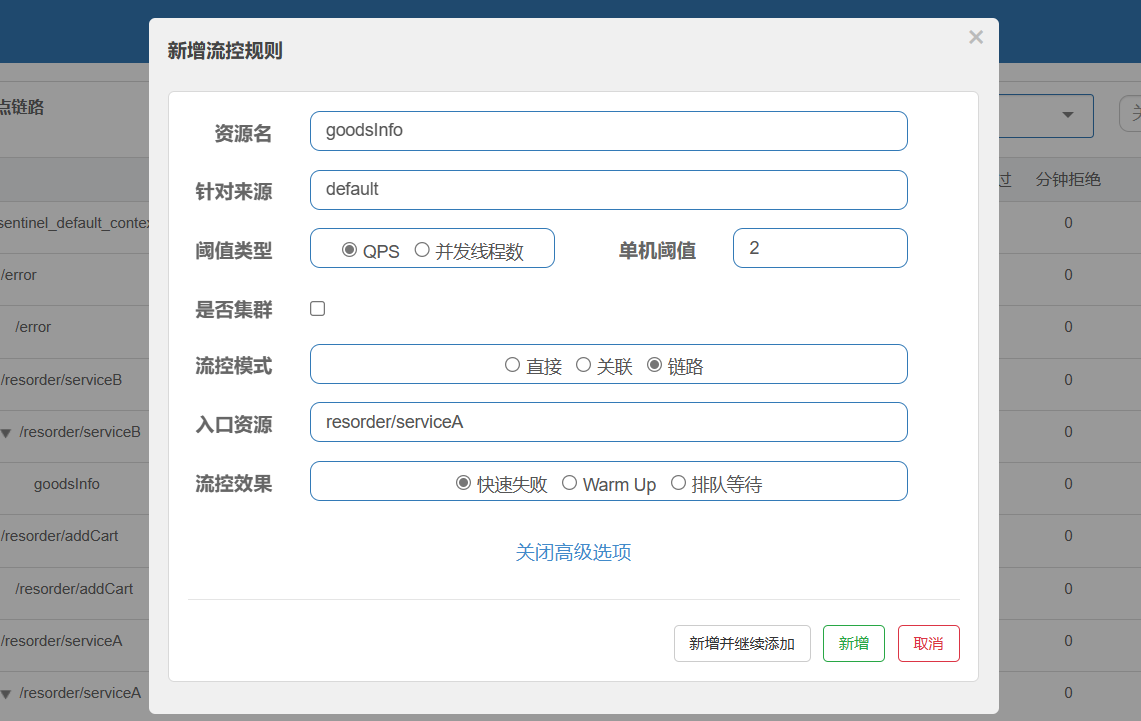
结果

授权规则
黑白名单控制
规则配置
来源访问控制规则(
AuthorityRule)非常简单,主要有以下配置项:
resource:资源名,即限流规则的作用对象。limitApp:对应的黑名单/白名单,不同 origin 用,分隔,如appA,appB。strategy:限制模式,AUTHORITY_WHITE为白名单模式,AUTHORITY_BLACK为黑名单模式,默认为白名单模式。配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。
官方文档: https://github.com/alibaba/Sentinel/wiki/黑白名单控制
系统自适应限流
系统规则
系统规则支持以下的模式:
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。- CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
推论
我们把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水,当系统处理顺畅的时候,请求不需要排队,直接从水管中穿过,这个请求的RT是最短的;反之,当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间。
- 推论一: 如果我们能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化。
接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,RT会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力。
- 推论二: 当保持入口的流量是水管出来的流量的最大的值的时候,可以最大利用水管的处理能力。
使用
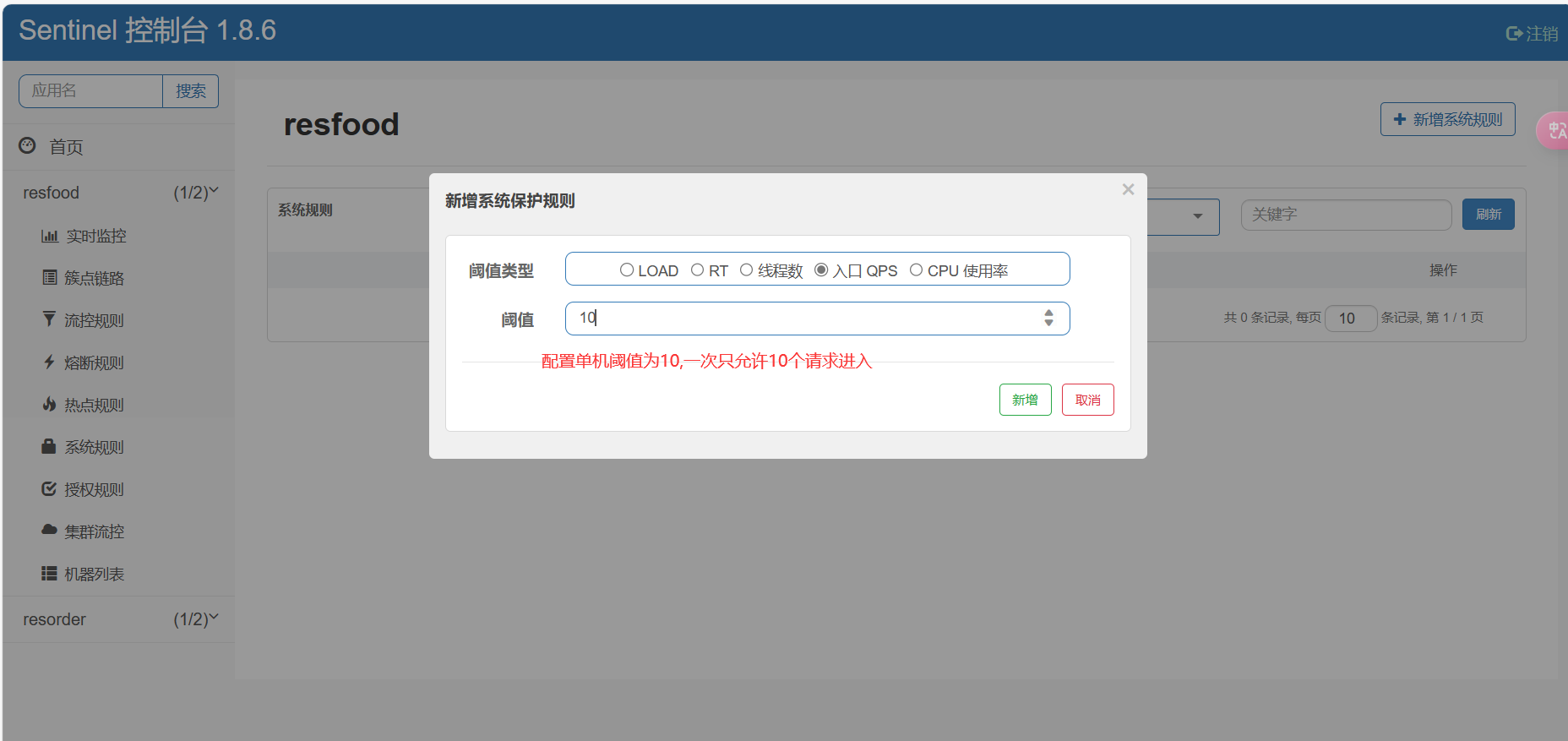
1.添加系统规则
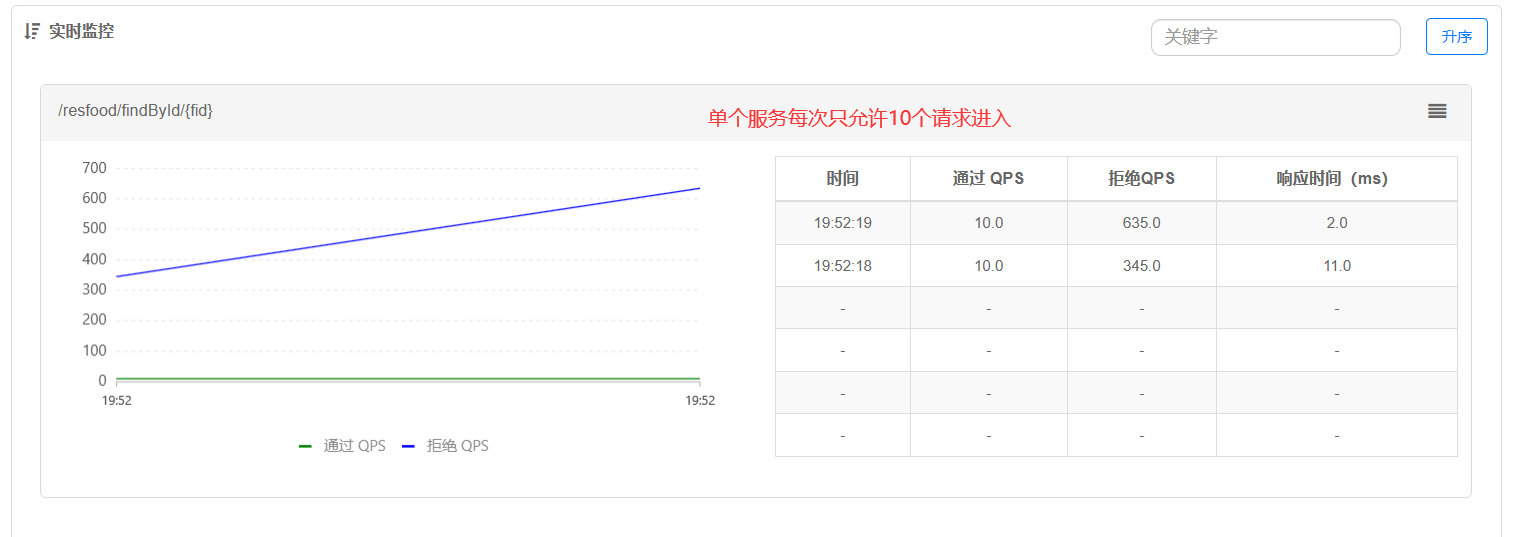
2.单服务流量分配
Apche Jmeter参数:
- 线程数 100
- Ramp-Up 1
- 循环次数 1
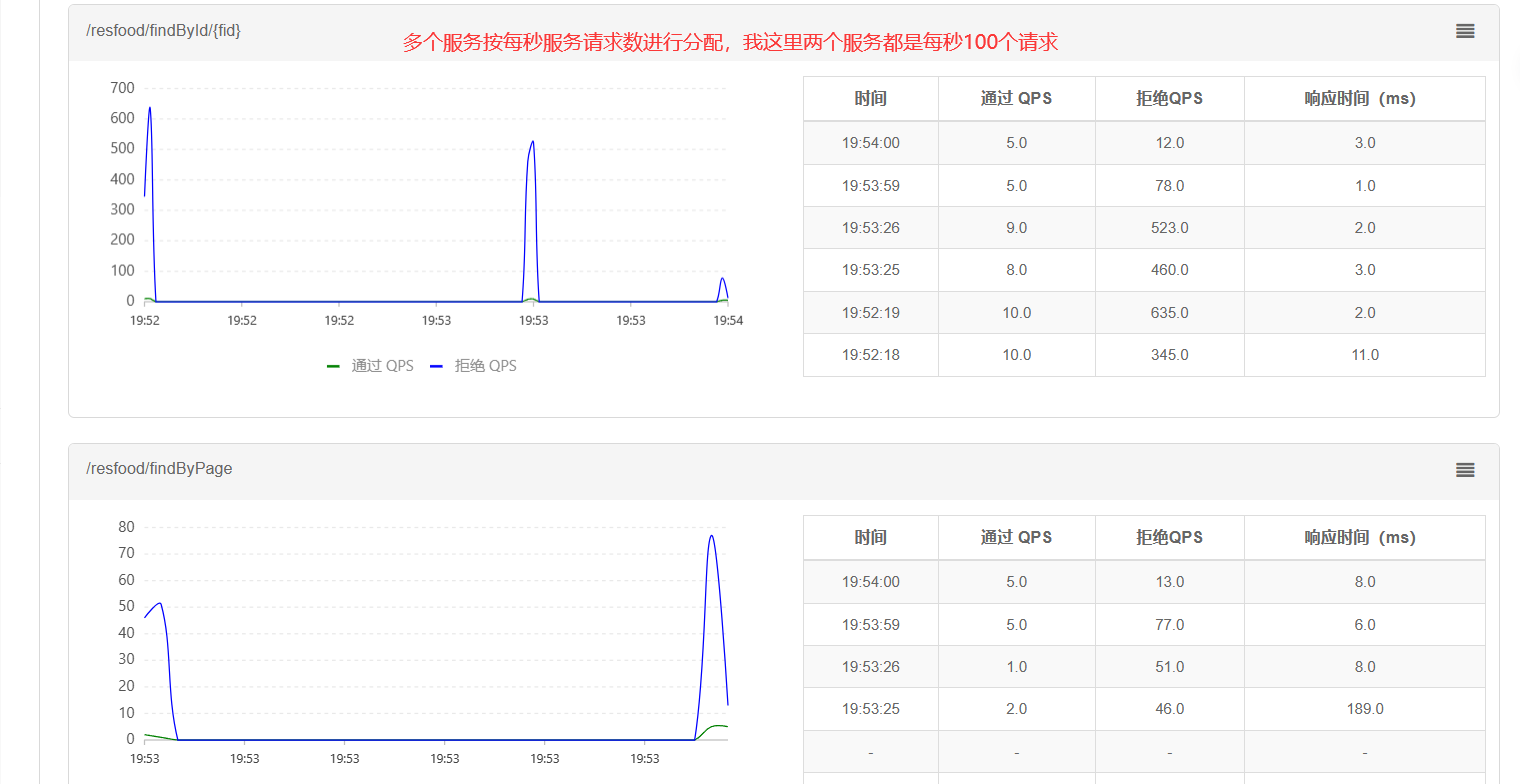
3.多服务流量分配
按每秒服务请求数比例进行分配
异常处理
流控异常处理
1 |
业务异常处理
当资源出现业务异常时,统一回调一个处理方法,重组异常信息
1 | //fallback 业务异常处理,handleException: 流控回调处理的方法名 |
1 | public Map<String,Object> handleException(Integer fid, Throwable exception){ |
异常的统一处理
 wechat
wechat- zhifubao

